作者:土土不怕苦_402 | 来源:互联网 | 2023-07-07 08:58
篇首语:本文由编程笔记#小编为大家整理,主要介绍了企业数字化转型:数据集成是成功的关键相关的知识,希望对你有一定的参考价值。
按照数据的生命周期,我们通常将大数据技术分为数据集成、数据存储、批/流处理、数据查询与分析、数据调度与编排、数据开发、BI 7 个部分。

数据集成是什么?
可以看到数据集成在数据生命周期的最前面位置,它负责将多个来自不同数据源的数据聚合存放在一个数据存储中(如数据仓库/数据湖),组合为用户提供单一统一视图,可以兼顾数据的增长量及所有不同的格式,合并所有类型的数据方便了后续的数据分析和挖掘工作。
做过数据工程的伙伴都知道,大数据项目中 90% 甚至更多的工作是和数据集成相关,数据集成有广泛的含义,包括数据清洗、数据抽取、数据转换、数据同步/复制 等操作。现如今的大数据生态系统已经发展得相当复杂(如下图),数据来源多种多样,如何把这么多来源的数据高效地聚合到数据湖/仓中,是数据集成重点要解决的问题, 也是数据集成的价值所在。
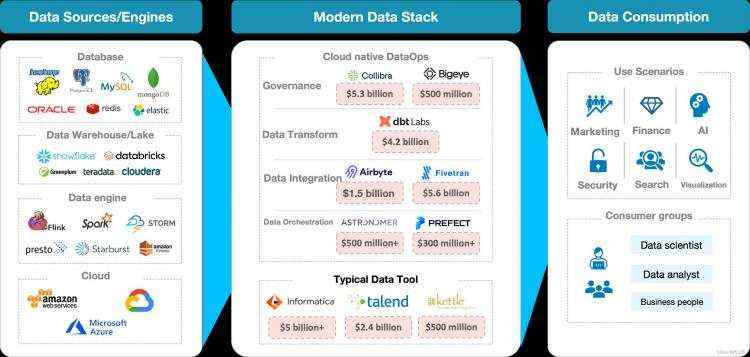
大数据生态系统概况
数据集成的业务场景
数据集成服务的常用业务场景如下:
- 同构/异构数据源间的同步:用户的原始数据需要转移存储,或利用目标存储系统的查询、分析能力,如 Hive 数据、本地数据需要同步到 Snowflake、Clickhouse 等做快速查询;
- 数据上云:用户需要把云下的数据快速安全的迁移到云上存储并做进一步的业务分析,如线下 mysql、Postgre 等到云上 RDS。
基于这些场景,数据集成一直以来都扮演着数据搬运工的角色,为各种各样的数据同步需求提供了强大高效的解决方案。
数据集成的常见策略
数据集成的两种常见策略:ETL 和 ELT
数据集成是数据工程师日常最耗时的工作之一。 什么是 ETL 呢? ETL 是传统的数据集成领域的一组特定流程,其中有三个重要阶段: Extract(提取), Transform(转换),Load(加载),它包括了数据抽取、转换、加载三个过程。ETL 是进行数据分析和挖掘工作前的准备过程。
先普及一下 ETL 和 ELT 的概念,
ETL 的过程为提取(Extract)→ 转换(Transform)→ 加载(Load), 在数据源抽取后首先进行转换,然后将转换的结果写入目标地(如数据仓库)。
ELT 的过程则是提取(Extract)→ 加载(Load)→ 转换(Transform),在抽取后将结果先写入目标地(数据仓库/数据湖), 然后利用数据仓库的分析能力或者如 Spark 、Presto 等引擎来完成转换操作。
没错,就是 Transform 和 Load 先后次序的问题,但影响非常不一样的,ELT 和 ETL 相比,最大的区别是 "重抽取和加载, 轻转换",从而可以用更轻量、快捷的搭建起一个数据湖/仓平台。使用 ELT 策略,在提取完成之后, 数据加载会立即开始。一方面更快速和高效,另一方面 ELT 允许数据分析人员访问整个原始数据,而不是经过数据工程处理后的 ”二手“ 收据,这为分析师提供了更大的灵活性,使之能更好地支持业务。
具体来说,在过去,由于计算和存储的高成本,ETL 方法曾是必要的。当年典型的 ETL 工具有:
商业软件:Informatica PowerCenter、IBM InfoSphere DataStage 、Microsoft SQL Server Integration Services 等
开源软件:Kettle、Talend、Sqoop 等
可以说这些软件都曾非常流行。但现在 ETL 正在面临着的问题:
1、不灵活。ETL 本质上是非常僵化的,它不仅需要数据工程师对原始数据按照数据仓库的规范进行层层处理,也迫使数据分析师提前知道要如何分析数据、如何产生报告。
2、不直观。对数据进行的每一次转换(Transform) 都会使一些原始信息 "消失"。数据分析师不能看到数据仓库中的所有数据,通常只能看到数据汇总层及数据集市层的数据,并且 ETL 的处理通常是十分耗时,经过层层的 ETL,时效性也很差。
3、不能自助使用。建立一个 ETL 的 Data Pipeline 通常超出数据分析师的技术能力,需要工程师的参与,这无疑加大了协作的代价。
随着硬件存储成本的急剧下降,在使用数据(L)之前,没有必要进行数据转换(T) 了,传统的 ETL 开始转变为 ELT。这使数据分析师能够以自主的方式完成更好的工作,具体来说,ELT 带来的 2 个明显好处是:
1、支持数据分析师的敏捷决策。原始数据被直接 Load 到数据仓库/湖中,构成一个 “单一的真实来源”,数据分析师可以根据需要对数据 进行转换。他们将始终能够回到原始数据,不会受到可能损害数据完整性的转换的影响。这使得商业智能过程变得无比灵活和安全。
2、ELT 降低了整个公司的技术难度。ELT 方法搭配 Looker、Tableau 等商业或者开源的 BI 工具可以被非专业技术用户所使用。
走 ELT 路线的开源软件有:Airbyte、Apache SeaTunnel。相信大家对 Airbyte 已经比较熟悉,这里我着重说说 Apache 基金会旗下开源的 SeaTunnel(Incubator) 这个已经在 Apache 孵化器中孵化了快 1 年的数据集成项目。
What is Apache SeaTunnel?
SeaTunnel is a very easy-to-use ultra-high-performance data integration platform that supports real-time synchronization of massive data. It can synchronize tens of billions of data stably and efficiently every day, and has been used in the production of nearly 100 companies.
SeaTunnel 的特性
- 丰富易扩展的 Connector:SeaTunnel提供了不依赖具体执行引擎的 Connector API,SeaTunnel 提供了一套不依赖于具体执行引擎的 SeaTunnel Connector API,基于这套API开发的 Connector(Source, Transform, Sink) 可以运行在多种不同的引擎上,目前支持 SeaTunnel Engine, Flink, Spark。
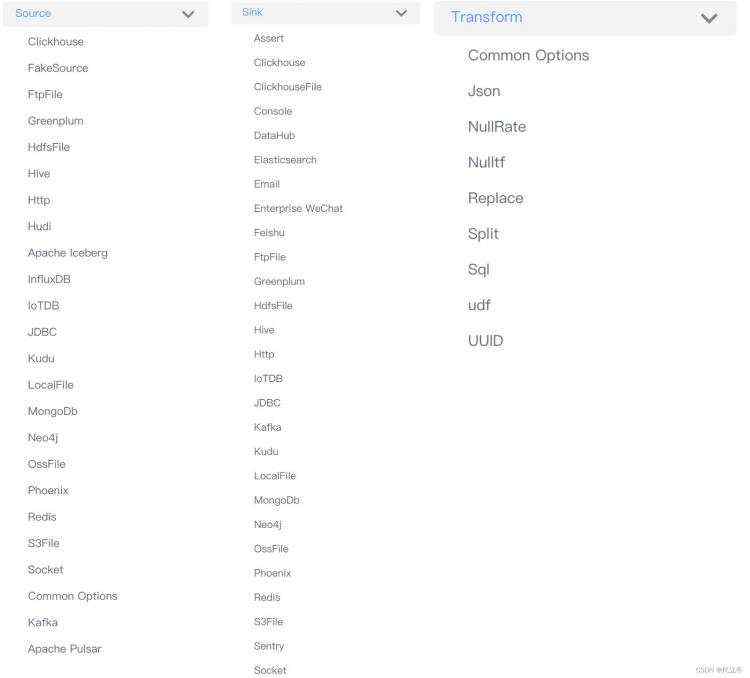
- Connector 插件化:插件化的设计让用户可以方便的开发自己的 Connector 并轻松集成到 SeaTunnel 项目中,目前 SeaTunnel 已经支持的 Connector 有 80 多个,这个数量正在以极快的速度增长。目前已经支持的连接器列表见下图。
- 批流一体:基于 SeaTunnel Connector API 开发的连接器可以完美兼容离线同步、实时同步、全量同步、增量同步等多种场景。这在极大程度上降低了数据集成任务管理的困难。
- 支持分布式快照算法,保证数据一致性。
- 多引擎支持:SeaTunnel 默认使用 SeaTunnel Engine 进行数据同步。同时为了适配企业已有的技术组件,SeaTunnel 还同时支持使用 Flink 或者 Spark 做为 Connector 的运行时执行引擎,SeaTunnel 支持多个 Spark 和 Flink 版本。
- JDBC 多路复用,数据库日志多表解析:SeaTunnel 支持多表或整库同步,解决 JDBC 连接数过多的问题;支持多表或整库数据库日志读取解析,解决 CDC 多表同步场景下需要重复读取和解析日志的问题。
- 高吞吐、低延时:SeaTunnel 支持并行读取和写入,提供了高吞吐低延时稳定可靠的数据同步能力。
- 完善的实时监控:SeaTunnel 正在支持数据同步过程中每一步的详细监控信息,让用户轻松了解同步任务读取和写入的数据条数、数据大小、QPS 等信息。
- 支持编码和画布设计两种作业开发方式:SeaTunnel web 项目中提供了作业可视化管理、调度、运行和监控能力。
SeaTunnel Connectors
SeaTunnel Connector 使用 Plugin 机制, 非常容易扩展, 当前 SeaTunnel 支持 80+ 种 Source、Sink(Target) Connector, 并且在快速发展中。
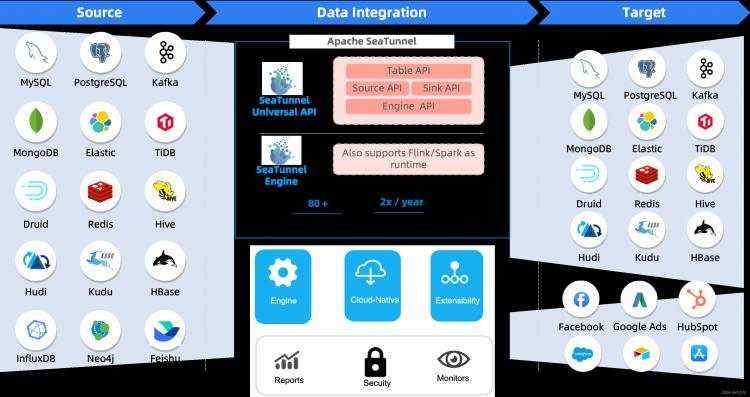
作为现代数据技术栈中的数据集成产品 - SeaTunnel 产品架构如下:
SeaTunnel 运行流程
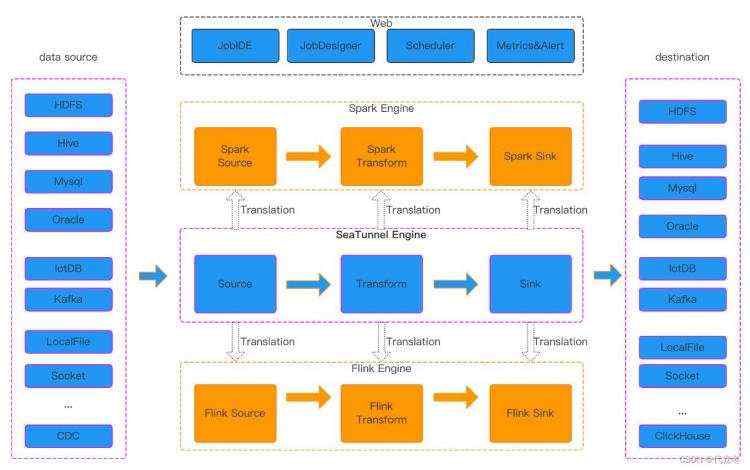
SeaTunnel 的运行时流程如上图,用户配置作业信息并选择执行引擎提交作业,Source Connector 负责并行数据数据并将数据发送给下游 Transform 或直接发送给 Sink,由 Sink 将数据写入目的地。值得注意的是,Source 和 Transform 和 Sink 都是可以由您自己轻松开发扩展的。除了使用 SeaTunnel 自己的引擎外,您也可以选择使用 Flink 或 Spark 引擎,这种情况下 SeaTunnel 会将 Connector 包装成 Flink 或 Spark 的程序,并提交到 Flink 或 Spark 集群中运行。
Quick Start for SeaTunnel
请参考官网:Set Up with Locally | Apache SeaTunnel ,
You could start the application by the following commands
- Spark
- Flink
- SeaTunnel Engine
cd "apache-seatunnel-incubating-$version"
./bin/seatunnel.sh \\
--config ./config/seatunnel.streaming.conf.template -e local
当然也可以通过 Kubernetes 等部署方式来体验。
写到这里,数据集成还包括一种数据虚拟化策略,数据虚拟化的优点是通过统一的 “视图” 来访问不同数据源,不需要对不同来源的数据源进行架构调整,另外对数据安全性要求较高的企业,不允许对数据进行复制的场景下,数据虚拟化是很好的解决方案。但数据虚拟化有以下待解决问题:无法解决性能和数据质量问题,随着企业数据量的不断增大,性能问题是所有数据集成都面临的问题,由于设计思路的缺陷,数据虚拟化在这方面虽有快速进展,但也无法和一些数据集成技术相比。数据质量管控意味着需要按照数据校验规则执行判断,这也不是数据虚拟化优先考虑的因素。这就导致数据虚拟化模式不适用对数据质量要求较高,需要进行大量数据转换、加工的场景如数据治理等。
关于数据虚拟化这个话题暂时到这里
小结
数据集成是消除企业信息孤岛,实现数据共享,是现代数据技术栈成功的关键,进而为企业实现数据治理提供扎实的 ”hardcore“ 。
数据集成可以将企业本地数据、SaaS 数据等不同“孤岛”的数据连接起来,让数据不在孤立,从而挖掘出更大的价值。
数据集成可以让企业的应用、流程、系统、组织和人员等关键要素都协同起来,提高企业业务效率。
数据集成可以将不同类型的数据聚合,让用户可以快速获得有用信息并迅速分析提炼出有价值的信息,从而提升数字化决策的成功率。











 京公网安备 11010802041100号
京公网安备 11010802041100号